你为什么记不住长单词
太长不看:
- 人类大脑在进行高级认知活动时受限于工作记忆(working memory) 的容量,而工作记忆的平均大小为 4 个组块(chunk)[1]。因此,当尝试一次性记忆超过 5 个字母的单词时,学生普遍感到开始吃力。这就是为什么大多数学生记忆长单词时会感觉困难。
- 我们可以通过分析长单词的音节 (syllable)、词根 (root)、词缀 (affix) 的构成进行拆解和分组,从而绕过上述的工作记忆容量限制。
正文
任何试图违反科学规律的努力都是一种傲慢,在学习之前我们首先需要「学习如何学习」,然而大多数学生对这方面的概念是一片空白。本文以中学阶段的英语学习为例,介绍现代认知心理学 (Cognitive psychology ) 中的重要概念「工作记忆」,它是我后续文章的叙述起点,对这个概念的理解和运用也贯穿我的英语学习生涯。 那么先来回答最重要的问题——
何为工作记忆?
让我们先来做个实验。现在给你一串 11 位的电话号码,请你尝试记住它,数字为:
18330986544
你会扫视一遍这串数字,然后尝试把它在大脑里念一遍,于是脑海里有个声音开始说:
183-3098-6544
又或者你脑海里的声音是这样的:
183-309-86544
1833-098-6544
无论是哪一种,你的大脑都会不自觉地在潜意识里将这串数字分组,然后你会依照按照上述几种分组方式之一开始多次地默念,直到记住为止。 注意到了吗,在接收并记忆这串新信息的过程中,你的大脑自动将数字分成了 3 组,每组有 35 个数字,即 4±1 个数字。4 就是人类的工作记忆容量的平均大小 1。而上述的记住一串新数字的过程,这个「分组——默念——记忆」的这个过程,就已经调用了人类的工作记忆。
那么工作记忆到底是什么呢?将人类的大脑类比成手机的话,工作记忆就像是手机的运行内存 (ram ) [2]。运行内存支撑手机开启、运行 APP,同时运行的 APP 数量过多,内存爆满,系统的响应速度就会变慢;类似的,人类要一次性记住 5 个以上组块的信息时就会超出工作记忆的容量大小,记忆效率下降。维基百科上的定义是: 「工作记忆是一种容量有限、可以暂时保存信息的认知系统」。Alan Baddeley 认为: 「工作记忆一词指的是一种大脑系统,它提供语言理解、学习和推理等复杂认知任务所需信息的临时存储和操作」。 在迄今为止的英语教学过程中,我发现不少学生在对长单词 (complex and compound words) 的记忆屡屡出错,学生 M 在默写单词 difficulty 以及更复杂的单词时极易出现字母缺失、顺序颠倒等情况,就是因为他没有意识到需要避免一次性记忆超过 5 个组块的信息/单词。心理上体现为对长单词的拼写从中后段开始无法笃定,记忆中的模糊感增加,落笔时自我怀疑。几乎所有的长单词都应该被拆成 25 个组块后再记忆,而非被视作一个由 5 个以上的字符构成的整体。4 个字母就是最适中的单组块大小。我们需要把信息分组——嵌套——再记忆,通过这种分组的方式绕过工作记忆容量大小的限制。这就是为什么,虽然人类的工作记忆组块数量有限,但却可以记住无限的信息。
问题来了,长单词应该遵循什么规则拆解? 有两种方式,按照发音拆分的自然拼读法和按照字形拆分的词根词缀法。
1. 自然拼读法 (Phonics )
自然拼读法,简而言之就是将英文单词发音与特定的字母组合关联起来,通过其发音拼写出单词,或者是通过单词拼写反推出它的发音。英文中 70% 左右的单词都可以实现这一点。初学者一般先学音素 (phone) 后学音节 (syllable),中间辅以音标进行对照。以下是一张音素表:

(英式发音中的 44 个音素,基于流行的 Adrian Underhill 布局并由 TEFL Trainer 改编,图源: Your English Hub)
如果你想了解更多关于这 44 个音素的信息,还可以参考这个网站。当然,大多数人并不会这么系统地学习自然拼读法 (包括我 ) ,而是往往学得时间久多了就能自然而然地在拼写和发音之间建立模糊的映射。事实上很多学生都能在完全不知道自然拼读法这个概念时进行无意识地应用,源于早期学发音的阶段时,学校老师会一边拆解音节 (甚至是故意拉长原音节 ) 发音,一边在黑板上写下音节对应的字母组成。这就是最早的自然拼读法。 然而用「自然拼读法倒推单词拼写」的前提,是学生的发音是对的。毋须讳言,除北上广深等超一线城市外,当今国内大部分城市的应试英语教育仍然是「哑巴英语」。语言环境既不鼓励学生开口讲英语,不少学生的发音存在错误时,自然也就因为不开口而得不到纠正。错误的发音无法倒推出正确的拼写,发音与字母组同步记忆,一错俱错。 为了在绕过工作记忆容量限制的同时纠正这一点,在此介绍第二种辅助记忆长单词的手段: 构词法。

(图源: 笔者 2023 年 7 月 29 日的朋友圈)
2. 构词法 (Word Formation)
以传统语言学的划分来看,语法包括词法、句法两个大的方面,但不知是出于何种原因,国内英语在词法上的教学普遍显得滞后、浅显,更有甚者几乎付之阙如。我在这里说的并不是词源学 (Etymology) 或词法学 (Morphology) 也不是词汇学 (Lexicology),而是「单词构成」 Word Formation。即了解单词是如何构成的,如何逆向拆解单词。据对我本人接触过的 W 市中学生的观察,初二下学期末的学生词汇量大约在 1000 左右,这个词汇量大小已经足够支撑学生在单词之间建立起某种一致的、抽象的规则认知了,但他们普遍在初三甚至高中时对此仍然觉察甚微。奇怪的是,构词法并非什么讳莫如深的课外知识,而是明明白白出现在 九年义务教育全日制初级中学英语教学大纲 (试用修订版 ) ) 中的。

(图源: 九年义务教育全日制初级中学英语教学大纲 (试用修订版 ) )
那么什么是构词法?简单来说就是将复合词拆解至词根、词缀的形式。 还是作类比举例。从汉字的构造来看,大部分汉字由部首和笔画组合而成,部首是具有字形归类作用的表意偏旁,它按照汉字的形体结构取其相同部分排列在一起,以供检字之用。如在汉语词典中,一般将诸如“杨”、“松”、“柳”、“柏”等字放在“木”部。这不仅方便了我们的检索,而且给我们一个直观的感受,这些字所表达的意义都与树木相关。即使我们不认识其中某个字,我们也可大胆地进行一些合理的意义推断。我们常说的“认字认半个”就是这个原因。[3]在英语单词的构成中,同样也可找到类似的一些例子。如,把 work、teach、mix、print 等动词变为相应的名词,分别为 worker (工人)、teacher (老师)、mixer (搅拌器)、printer (打印机)。后缀 -er 表示动作对应的执行者/执行工具,它也是我们最早普遍接触到的一批词缀之一。 在 interview、international、interact、internet、interrupt 等单词中,共同的前缀 inter- 表明它们都包含“在… 之间”或“相互”的含义。具体拆解如下:
-
inter-view: 「互相之间的视野」->「采访」
-
inter-national: 「国家的互相之间」->「国际的」
-
inter-act: 「互相之间的动作」->「交互」
-
inter-net: 「互相之间的网」->「互联网」
-
inter-rupt: 「在……之间打断」->「打断」
由此可见,汉语中的“木”部与英语中的后缀 -er 以及前缀 inter- 都有明确的表意的功能。这些都是构成单词的表意单元,也是语言最小的有意义单位,即词素 (Morpheme)。中学阶段常见的其他前缀还包括 un-/in-/im-/re-/dis-/de-/mis-/ex-/trans-/en-/pre-/tele- 等等,就不一一列举了,而掌握这些词缀之后学生就能够有效地拆解、记忆单词。这是通过对单词本身的生成逻辑来记忆单词,显著的优点在于举一反三,通过对同一词缀的串联构成一次性记住大量的、同一词族下的新单词,扩大词汇量。它也能够在单词的构成和中文意思之间建立某种弱关联,有助于回忆,因为单词的含义就是根据它的构成来生成的。放在应试考试的视角下看,这些优点还多了一个新的适用之地,即在做「阅读理解」时面对陌生的单词,可以根据它的构成推测出词性,并以某种模糊的、内生的关联猜测单词的含义。换言之,对单词做逆向工程。[4]
现在再回过头来拆解一个单词作为练手: international adj. 国际的
-
按照音节,可拆解为: in-ter-na-tion-al /ɪn-tər-ˈnæʃən-əl/
-
按照词根词缀,可拆解为: inter-nation-al
-
还可以按照已经学过的单词,拆解为: inter-national 3.1. national 这个词在小学英语教材中已经出现过,大部分学生已经将其存储在长时记忆中,因此再次调用时只会占用 1 个组块 3.2. 认知负荷理论的核心概念是,我们处理新信息的心理带宽是有限的,但处理以前已经掌握的材料时却没有这样的限制
构词法不仅提供了拆分的依据和用于联想意思的词根词缀,也提供了固定字母组合对应的固定发音,比如 -tion 既是名词性的后缀,也通常发音成 /ʃən/,后缀 -ture 的发音为 /tʃər/ 或 /tʃɜːr/ (见于 sculpture、structure) 。因此构词法和自然拼读法两种拆解方式并不冲突,在某些情况下还会重叠,两者共同辅助记忆。如果后期系统性地学习掌握之后,还可以画树状图对单词进行形态结构分析,更加看得一清二楚。比如单词 disproportionately 可以拆解如下:
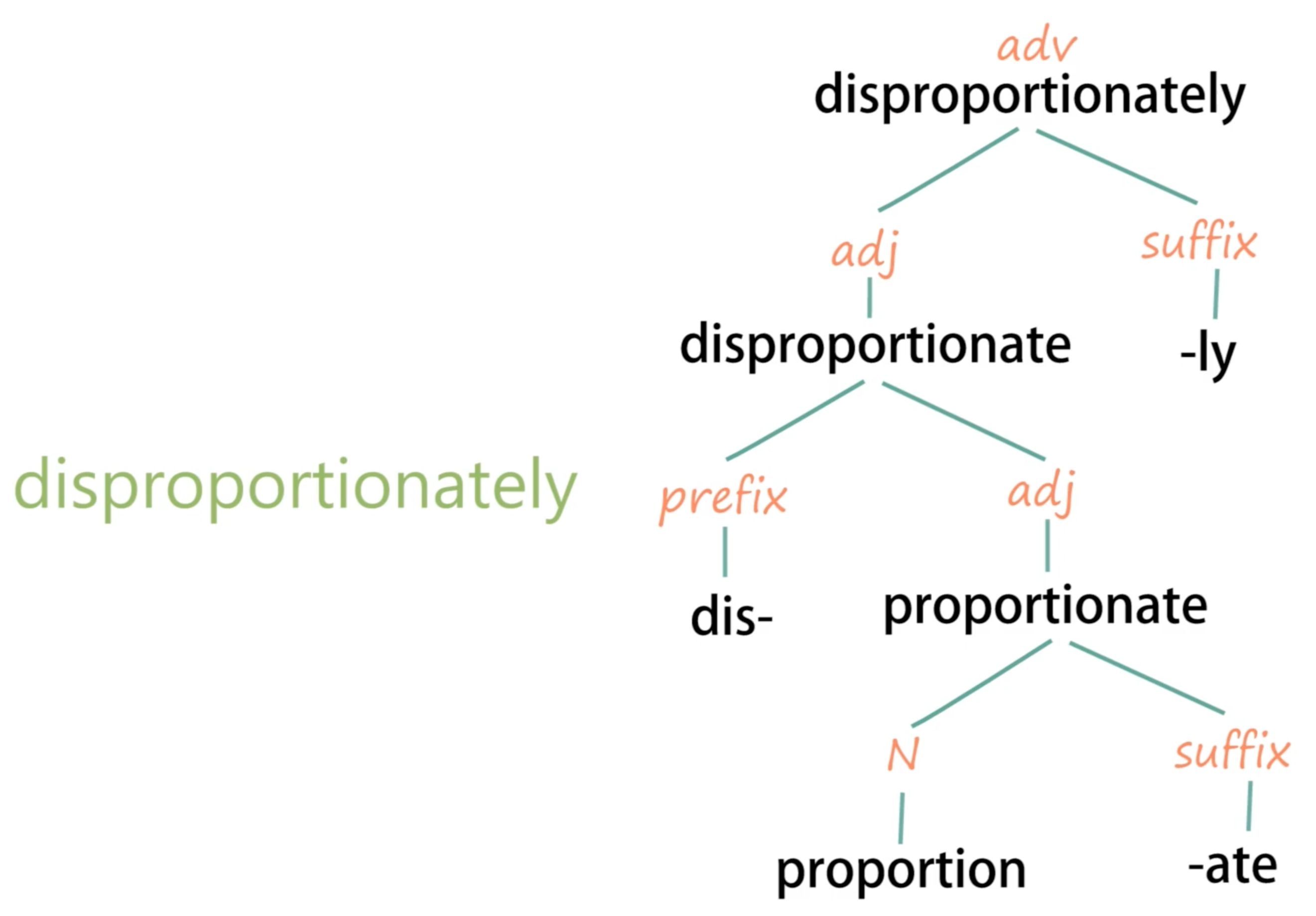
如此一来,一个 18 个字母的单词被拆成了前缀 dis-,词根 proportion,后缀 -ate,后缀 -ly 四部分,每块对应的意思分别是是 「不 — 比例 — 成 — 地」,合起来就是「不成比例地」。词根 proportion 的发音遵循标准规则,因此也可以用自然拼读法拆解。由此我们得以欺骗大脑,大大降低了记忆一个长单词的工作量。
以上,下次再见。
参考资料:
作为对比,猕猴的工作记忆大小介于 3 和 4 之间 ↩︎
虽然严格来说工作记忆更像是寄存器 (register ) ,而不是缓存 (ram ) : 数量极其有限,直接用于处理器运算 ↩︎
这一段参考了百度百科语言迁移 #语言迁移与英语语法教学 ↩︎
事实上,英语的构词法相对简单,复合词也普遍由 23 个单词组成,所以有时即使单词拆解得很粗糙也能学。相较而言,德语中的复合词则可以无限制地组合,创造出非常长的单词,德语的单词也普遍更长一些。比如德语中的花名「勿忘我」: Vergissmeinnicht,16 个字母拆解成三块: Vergiss- (忘记 ) -mein (我的 ) -nicht (不要 ) 。极端一点的例子还有 Donaudampfschifffahrtsgesellschaftskapitän 「多瑙河汽船公司船长」,由 42 个字母组成,可供拆解成 6 块。掌握构词法来拆解单词是学习英德法等一众字母语言的必要手段。 ↩︎